
Как человек, внимательно следящий за разработками в области искусственного интеллекта, я воодушевлен представлением Apple своих моделей OpenELM. Возможность запускать небольшие языковые модели на локальных устройствах, таких как смартфоны, является значительным достижением, которое может привести к созданию более сохраняющих конфиденциальность и эффективных приложений искусственного интеллекта.
Купил акции по совету друга? А друг уже продал. Здесь мы учимся думать своей головой и читать отчётность, а не слушать советы.
Прочитать отчет 10-KВ сфере искусственного интеллекта (ИИ) наблюдается всплеск интереса к «компактным языковым моделям». Эти модели являются предпочтительными, поскольку ими можно управлять на локальных устройствах, а не полагаться на мощные компьютеры, расположенные в центрах обработки данных, которые обычно требуются для более крупных приложений искусственного интеллекта. В среду Apple представила коллекцию миниатюрных языковых моделей искусственного интеллекта под названием OpenELM, которые достаточно легки, чтобы без проблем работать на смартфонах. В настоящее время эти модели служат экспериментальными исследовательскими проектами, но потенциально они могут проложить путь для будущих решений Apple в области искусственного интеллекта на устройствах.
Я заметил, что Apple недавно представила набор новых моделей искусственного интеллекта, которые они вместе назвали OpenELM или «Эффективные языковые модели с открытым исходным кодом». Эти модели можно найти на Hugging Face, и они доступны по лицензии Apple Sample Code License. Хотя эта лицензия не полностью соответствует типичному определению «открытого исходного кода», исходный код OpenELM действительно открыт для общественности.
Во вторник мы обсуждали модели Microsoft Phi-3, которые стремятся к сопоставимому уровню понимания языка и скорости обработки в компактных системах искусственного интеллекта, которые могут работать локально. Модель Phi-3-mini состоит из 3,8 миллиардов параметров, тогда как модели Apple OpenELM варьируются от 270 миллионов до 3 миллиардов параметров в восьми различных моделях.
Со стороны я заметил, что самый обширный член серии Llama 3 от Meta может похвастаться параметрическим весом в 70 миллиардов, и в разработке находится даже версия на 400 миллиардов. С другой стороны, GPT-3 от OpenAI, созданный два года назад, имел впечатляющие 175 миллиардов параметров. Количество параметров часто используется как приблизительный показатель возможностей и сложности модели ИИ. Однако недавние исследования сместили акцент на создание меньших языковых моделей, которые могут соответствовать возможностям более крупных моделей, созданных всего несколько лет назад.
Доступно восемь моделей OpenELM, разделенных на две категории. Две из этих моделей служат «предварительно обученными» версиями, которые можно рассматривать как неизмененные модели, готовые к обработке следующего токена. Остальные шесть моделей подверглись «настройке инструкций», что сделало их более подходящими для таких задач, как создание ИИ-помощников и чат-ботов, которые эффективно следуют инструкциям.
- ОпенЭЛМ-270М
- ОпенЕЛМ-450М
- ОпенЕЛМ-1_1B
- ОпенЕЛМ-3Б
- OpenELM-270M-Инструкция
- OpenELM-450M-Инструкция
- OpenELM-1_1B-Инструкция
- OpenELM-3B-Инструкция
Я заметил, что OpenELM имеет максимальное контекстное окно в 2048 токенов. Для создания этих моделей были использованы данные из общедоступных наборов, таких как RefinedWeb, уточненный PILE без дублирования, часть RedPajama и сегмент Dolma v1.6. Apple сообщает, что общая сумма этих наборов данных составляет примерно 1,8 триллиона токенов. Эти токены служат фрагментированными представлениями данных, используемыми моделями языка искусственного интеллекта для эффективной обработки.
Методология Apple OpenELM, как объяснил технологический гигант, использует эффективную «стратегию масштабирования слоев», которая, очевидно, более экономично распределяет параметры по каждому уровню. Этот подход не только экономит вычислительные ресурсы, но и повышает производительность модели во время обучения, используя меньшее количество токенов предварительного обучения. Согласно данным официального документа Apple, эта тактика привела к повышению точности на 2,36% по сравнению с OLMo 1B от Allen AI, при этом потребовалось лишь вдвое меньше необходимых токенов для предварительного обучения.
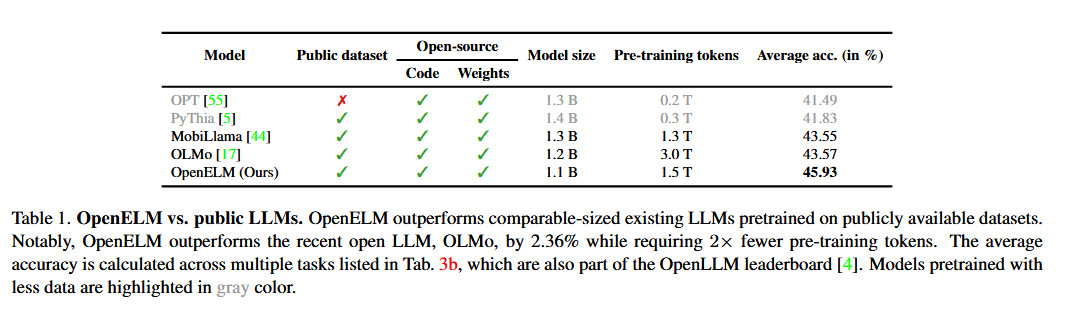
Apple сделала необычный шаг среди крупных технологических компаний, опубликовав код для CoreNet, их библиотеки, используемой при обучении OpenELM, а также обучающие рецепты, позволяющие репликацию файлов нейронной сети. Согласно аннотации статьи Apple OpenELM, прозрачность является для них приоритетом: «Прозрачность необходима для продвижения открытых исследований, поддержания достоверности результатов и обеспечения возможности исследовать предвзятости данных и моделей, а также потенциальных опасностей».
Решение Apple поделиться исходным кодом, весами моделей и данными обучения призвано «дать исследователям импульс и расширить сферу открытых расследований». Однако важно отметить, что, поскольку эти модели были разработаны с использованием общедоступных наборов данных, существует риск того, что они могут генерировать неправильные, вредные, предвзятые или оскорбительные ответы, когда пользователи предоставляют подсказки.
Я заметил, что Apple на данный момент не внедрила последние достижения в области языковых моделей искусственного интеллекта в свои потребительские устройства. Тем не менее, ходят слухи о новых возможностях искусственного интеллекта, которые появятся в ожидаемом обновлении iOS 18, которое, как ожидается, будет представлено на WWDC в июне. Предполагается, что эти функции используют обработку на устройстве для обеспечения приоритета конфиденциальности пользователей. Тем не менее, Apple могла бы также рассмотреть возможность передачи более сложных задач обработки искусственного интеллекта за пределами устройства отраслевым гигантам, таким как Google или OpenAI, чтобы значительно повысить производительность Siri.
Смотрите также
- 20 лучших циферблатов Samsung Galaxy Watch, которые вам стоит использовать
- XDC криптовалюта и прогнозы цен на XDC
- Инженер-пенсионер обнаружил ошибку 55-летней давности в коде компьютерной игры Lunar Lander
- Intel «отвратительно» отклонила некоторые возвраты дефектных процессоров, говорит YouTuber
- OnePlus 15 против Oppo Find X9 Pro: Флагманы в сравнении
- Huawei Watch GT 6 Pro против GT 5 Pro: Что нового в этом носимом устройстве?
- 6 лучших планшетов для путешествий в 2024 году
- «Голова папы» и «Демоническое расстройство» от Shudder Originals будут доступны для просмотра этой осенью
- Сравнение камер Samsung Galaxy S25 Plus и OnePlus 13
- INJ криптовалюта и прогнозы цен на INJ
2024-04-26 00:25