
Google не существовало при первом введении Всемирной паутины, но позже сформировал ее согласно своим собственным правилам. Сейчас любой сайт, стремящийся к видимости, должен соблюдать регуляции Google. После многих лет господства в поисковых системах, Google недавно столкнулся с крупным антимонопольным иском, который может коренным образом изменить как компанию, так и Всемирную сеть, какой мы её знаем.
Купил акции по совету друга? А друг уже продал. Здесь мы учимся думать своей головой и читать отчётность, а не слушать советы.
Прочитать отчет 10-K* На прошлой неделе закончились заключительные аргументы по делу, и ожидается решение в августе от Министерства юстиции США для компании Google. В случае проигрыша Google могут грозить серьезные штрафы, включая потенциальную потерю Chrome. Однако Министерство также рассматривает другие решения, которые могли бы иметь долгосрочные последствия.
* Во время своих показаний генеральный директор Google Сундар Пичаи выразил обеспокоенность идеей обязательности предоставления лицензий на поисковый индекс и алгоритм Google, являющиеся ключевыми аспектами этого дела. Он заявил, что это по сути означало бы отделение Google Search от основного бизнеса компании. Иногда компания шуточно называет этот процесс «белой этикеткой» для своего поиска.
Возможно, не кажется таким ужасным иметь версию поисковика от Гугл под своим брендом, учитывая его широкий и непревзойденный индекс веба. Однако способ представления результатов вызывает разочарование у многих пользователей. Меньшие поисковые компании пытались предложить альтернативы инструментам поиска Гугла, каждая со своими уникальными методами извлечения информации. Они все согласны с тем, что разделение Google Search могло бы снова революционизировать веб. Вопрос о пользе этих изменений остается субъективным и зависит от того, кого вы спросите.
Интернет большой и шумный
За годы существования результаты поиска Google эволюционировали, что заставило некоторых пользователей искать альтернативы. Некоторые перешли на чат-ботов с искусственным интеллектом для получения ответов, не обращая внимания на возможные галлюцинации. Тем не менее, большинство людей все еще предпочитает классические 10 синих ссылок (пока что).
Ввиду обширности интернета существуют три основных базы данных для поиска в интернете: Google, Bing и Brave. Любой поисковый инструмент, включая искусственный интеллект, использует одну или несколько из этих баз данных для нахождения информации в сети. Проще говоря, это значит, что эти базы помогают нам получить доступ к нужным данным при проведении поиска онлайн.
По сути, Хосеп Пужол из Brawe объясняет, что поисковый индекс работает как полезный ассистент в интернете. Когда вы задаёте ему вопрос или запрос, он может найти подходящие веб-страницы или документы, опубликованные ранее онлайн.
В качестве исследователя, занимающегося технологиями поиска, я пришел к пониманию того, что поисковый индекс – это по сути огромный репозиторий данных, но он не эквивалентен поисковым результатам. Чтобы пояснить: даже если у нас есть самый всеобъемлющий и превосходный поисковый индекс в мире, это не гарантирует удовлетворительных результатов показа для конкретного запроса, как верно отметил JP Schmetz, руководитель рекламы в Brave.
Передовые технологии Google позволяют ей исследовать больше вебсайтов, чем любая другая служба. Это охватывает ключевые сайты, специализированные ресурсы, заброшенные блоги, сомнительные копии аутентичных сайтов, клоны этих копий, версии скопированных реплик, переписанные искусственным интеллектом, и так далее – по сути, «всё». Результатом этого масштабного цифрового каталогирования является поисковый опыт, который иногда может показаться неорганизованным или запутанным.
Выступая как сторонник, скажу: поразительно наблюдать, как Google проводит масштабные испытания, оставляя конкурентов позади. Это происходит потому, что их огромный размер создает уникальное ‘слепое пятно’. Преимущество масштаба порождает самоподкрепляющий цикл сетевых эффектов, который удерживает компанию на вершине и делает сложным для конкурентов догнать ее и сократить отставание.
Хотя размер индекса поисковой системы может казаться решающим фактором, это не единственный аспект, который стоит учитывать. Например, браузер Brave знаменит своим браузером и также обладает собственной поисковой системой — Brave Search. По умолчанию она используется в браузере Brave, но ее можно открыть напрямую через URL на вашем текущем браузере. В отличие от многих других поисковых систем, Brave не полагается на внешние источники для получения результатов. Пужол утверждает, что Brave способен эффективно предоставлять необходимую информацию без зависимости от масштаба индекса Google. Интересно, что результаты поиска Brave могут даже превосходить те, что выдает Google, обеспечивая более объективные и не подправленные данные.
Объем индекса Brave охватывает около 25 миллиардов веб-страниц, однако значительная часть остается неисследованной. Возможно, мы могли бы индексировать до пяти до десяти раз больше страниц, но сознательно не делаем этого, поскольку не весь интернет содержит полезную информацию. Большинство веб-страниц по сути являются фоновым шумом, согласно Пуджолу.
Kagi, поисковик для бесплатной информации, не ставит своей главной целью самую широкую базу данных. Вместо этого он работает как метапоисковый движок, собирая данные из различных источников, включая Bing и Brave. Вместе с тем Kagi поддерживает свой уникальный индекс, который его основатель и генеральный директор Владимир Преловац называет ‘некоммерческим веб’ (the non-commercial web). Это означает, что KagI сосредоточен на некоммерческом контенте.
При использовании Kagı для поиска вы можете заметить, что некоторые результаты (показывает соотношение) берутся из уникального индекса сайта, состоящего из персональных блогов, хобби-вебсайтов и реже встречающегося контента. Это напоминало времена, когда крупные корпорации не всегда доминировали в результатах поисковых систем Google — однако доступ к этим данным постепенно становится сложнее получить вследствие приоритетности ИИ, рекламы, данных Knowledge Graph и других функций Google. По словам Prelovaća, именно поэтому был создан Kagı.
Спинофф компании Google мог бы все изменить
Стало очевидно для многих, что Гугл изменил свою стратегию поиска, делая сложнее находить достоверную и точную информацию для людей. Тем не менее, несмотря на эту проблему, остается высокая потребность в обширной и полной базе данных веба от Google.
Несмотря на альтернативы вроде Bing и Brave, некоторые компании прилагают огромные усилия для распространения результатов поиска Google. Неофициальная индустрия возникла, которая собирает данные поисковых запросов Google вместо подлинного индекса. Эти фирмы пренебрегают правилами Google, однако их результаты появляются в результатах поисковой выдачи Google. Похоже, что Google способен решить эту проблему, если захочет.
Министерство юстиции считает огромные объёмы данных у Google основополагающим строительным материалом для создания универсальной поисковой системы. Они уверены, что требование к предоставлению доступа к этим данным является критическим шагом в разрушении монополии Google. Если предложенные Министерством юстиции решения по доступу к данным будут реализованы, подозрительные синдикационные фирмы исчезнут, открывая легальные возможности для конкурентов использовать индекс Google. И они определённо сделают это.

По объяснению Преловаца, такая ситуация может привести к увеличению разнообразия выбора при поиске. В сущности, он утверждает, что Закон Шермана направлен на поддержку конкурентной рыночной среды. Благодаря доступу к индексу поисковых запросов могут появиться и процветать многочисленные поисковые стартапы.
Создатель Kagri предложил возможность получения лицензии для поиска от Google. Это могло бы позволить организациям различных масштабов — начиная с малых бизнесов и заканчивая городами — разрабатывать специализированные, действительно полезные поисковые инструменты под их нужды. Например, города могли бы использовать эти данные для создания детально проработанных поисковых систем, учитывающих особенности местоположения, в то время как любители кошек могли бы создать поисковую систему исключительно для кошек, опираясь на обширнейшую базу данных онлайн-контента. Кроме того, универсальные сервисы поиска, такие как Kagri, были бы допущены к лицензированию технологии Google за относительно скромную плату, как упоминает Министерство юстиции.
Без промедления Преловац подтвердил, что Kagami, известный ограниченным количеством бесплатных поисков до подписки, открыт к интеграции индекса Google. По его словам: ‘Абсолютно, это то, что мы могли бы рассмотреть’. И он добавил: ‘Я думаю, что это стоит сделать.’
Возможны потенциальные недостатки в предоставлении услуг поиска Google бесплатно. Судья Амит Мехта выразил опасения, что предотвращение заключения сделок о размещении рекламы в результатах поиска может ограничить выбор браузеров, и есть сопоставимые проблемы относительно решений по данным. Если Google будет вынужден предложить свою технологию поиска как API, его сравнительно небольшие конкуренты в области индексации веб-страниц могут столкнуться с трудностями выживания. В некотором парадоксальном смысле распространение технологии поиска Google могло бы усилить её доминирование.
Как сторонник Brave, я разделяю их опасения по поводу того, что технология поиска Google станет легкодоступной. Если это изменение будет внесено без тщательного обдумывания, оно может привести к серьезным проблемам в отношении веб-разнообразия. По словам директора рекламы Brave JP Schmetz: «Если суд обяжет Google предоставлять поисковую услугу по низкой стоимости, мелким игрокам вроде Bing и Brave придется бороться за выживание до тех пор, пока проблема не будет решена.»
Рельеф местности поиска под управлением ИИ может измениться. Показания в процессе судебного разбирательства от Ника Терли из OpenAI показали, что они пытались, но не смогли обеспечить доступ к Google Search для своих моделей искусственного интеллекта, используя вместо этого Bing. Если Google станет возможным вариантом в будущем, вероятно, OpenAI и другие компании по разработке ИИ быстро рассмотрят возможность связывания веб-данных Google со своими большими языковыми моделями (LLM).
Согласно словам Брайана Брауна, главы бизнес-подразделения Brave Chief, попытки уменьшить влияние Google могут непреднамеренно предоставить ему дополнительные монополии в области искусственного интеллекта. По его словам: ‘Внезапно вы получите одиночный монолит как источник истины для всех моделей обучения языкам (LLM) и всего интернета.’
Что если вы не продукт?
Если Google расширит свои предложения под собственной маркой, это может обогатить разнообразие доступных поисковых услуг, возможно жертвуя другими индексами в процессе. Такая диверсификация может способствовать процветанию менее рекламных поисковых продуктов — явление редко наблюдаемое сегодня.
Как исследователь, изучающий мир веб-поиска, я понял, что для большинства пользователей эта услуга всегда была бесплатной, финансируемой главным образом за счет рекламы. Компании такие как Google, Brave, DuckDuckGo и Bing предоставляют неограниченный доступ к поисковым запросам без какой-либо платы, но их истинная мотивация – привлечение внимания пользователей (или ‘глаз’). Часто повторяемая мысль остается верной: когда что-то кажется слишком хорошим для того чтобы быть правдой, это потому, что вы, пользователь, являетесь продуктом, который продается. Этот бизнес-модель, хотя и принимается многими, вызывает у меня вопросы, особенно те, которые были высказаны основателем Kagia.
По словам Преловача, когда дело доходит до получения критически важной информации, я предпочитаю прямую связь без посредников, особенно тех, кто имеет личные интересы и может пытаться что-то мне продать.
Результаты поиска Kaggi признают отрицательное влияние современного рекламного режима. Пользователи Kaggi видят предупреждение рядом с результатами, содержащими большое количество рекламы и трекеров. По словам Prelovać, это является самым сильным признаком низкого качества результата. Этот значок также позволяет регулировать распространенность таких сайтов в ваших персональных результатах. Вы можете понизить рейтинг сайта или полностью скрыть его, что представляет собой ценную опцию в эпоху кликбейта.
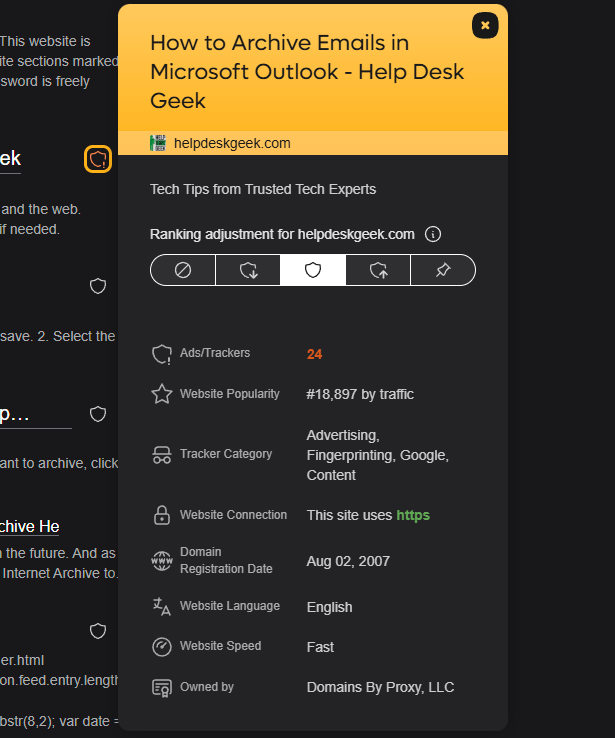
Согласно Преловацу, способ Каги взимания платы за поиск изменяет характер взаимодействия данных с ними. Проще говоря, он заявил: ‘Нам вообще не требуется пользовательские данные’. Однако дело не только в том, что они нам не нужны; вместо этого, это может стать бременем или риском.’
Преловац открыто признал, что заставить людей платить за поисковые услуги может быть невероятно сложно. Однако он утверждает, что полагаться на рекламу для поддержки поисковых движков является тупиком. Следовательно, Каги предполагает будущее через пять или десять лет, когда люди придут к пониманию того, что фактически платят за поддерживаемые рекламой поисковые системы через потерянное время продуктивности и личные данные.
Общеизвестно, что Google накапливает значительное количество пользовательских данных. Тем не менее возникает вопрос: какие последствия это имеет для меньших поисковых систем, таких как Brave и DuckDuckGo, которые в основном зависят от рекламных доходов?
Я уверен, что они делают все возможное добронамеренно,
Храброе обеспечивает конфиденциальность пользовательских данных, используя трекинг от первого лица для связывания кликов с Brave, вместо прямого взаимодействия с пользователем. Как заявил JP Schmetz из Brave, не будет возможности нацеливать рекламу на конкретных людей в будущем, и таких действий сейчас не происходит.
Дакдакго функционирует немного иначе; хотя он использует обширную базу данных поиска Bing в качестве основы, дополнительно предоставляет дополнительные функции для обеспечения конфиденциальности. Как Google и Brave, сервис предлагает свои услуги бесплатно и поддерживает рекламу, но Дакдакго подчеркивает свою приверженность защите приватности пользователей.
Как преданный поклонник, я хотел бы поделиться некоторыми захватывающими новостями о моей любимой поисковой системе DuckDuckGo. Согласно их собственному заявлению, DuckDuckGo обеспечивает приватность пользователей при просмотре рекламы путем сотрудничества с рекламной сетью Microsoft. Представитель компании Kamyl Bazbaz подробно рассказал, что это партнерство препятствует отслеживанию пользователей или созданию профилей на основе кликов. Кроме того, у них есть аналогичные обязательства по обеспечению приватности пользователей в отношении TripAdvisor для туристической рекламы.
Это ИИ до самого низа.
Игнорируя гигантов искусственного интеллекта, которые сегодня доминируют в ландшафте поиска, можно представить привлекательным потенциальное ответвление Google как способ обойти эту тенденцию. Однако в ближайшем будущем может оказаться сложным найти пути отхода от этого направления. Будущее поиска вполне может отклоняться от традиционного формата 10 синих ссылок и стремиться к модели ассистента на основе искусственного интеллекта.
Большинство поисковых систем, за исключением Google, включают ИИ в свою работу. Яркий пример этого — Microsoft Bing, сотрудничающий с OpenAI. Даже меньшие игроки на этом поле предлагают возможности поиска на основе ИИ. Разработчики таких продуктов соглашаются как с Microsoft, так и с Google по важному вопросу: они считают, что ИИ является неизбежной частью будущего.
Сегодняшние поисковые системы вроде Bing или DuckDuckGo имеют свои уникальные подходы к сумматированию искусственного интеллекта, предоставляя ответы на вопросы путем анализа поисковых результатов. По сравнению с Google AI они кажутся более осторожными в своем применении. В то время как Google и Microsoft активно развивают поиск на базе ИИ, другие провайдеры поиска кажется довольными следовать этой тенденции, а не вести ее.Другие поисковые системы используют свои собственные методы применения ИИ для ответа на вопросы, что менее заметно по сравнению с использованием искусственного интеллекта в Google.
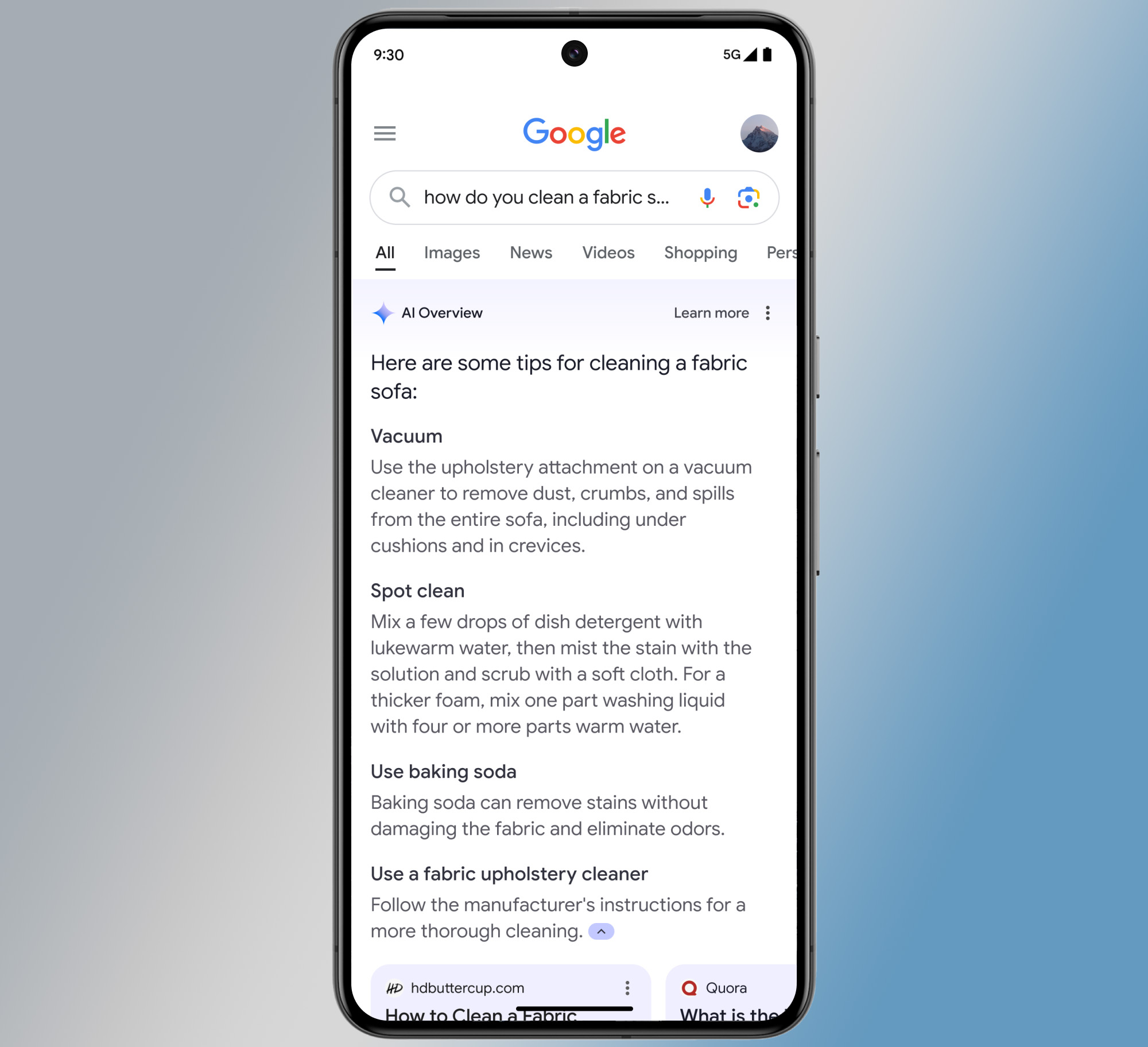
В соответствии с Bazbazom, некоторые люди предпочитают начинать поиск в формате чата перед тем как перейти к обычным результатам поиска по необходимости, тогда как другие делают наоборот. Для того чтобы удовлетворить все предпочтения, мы решили предоставить обе опции. Мы сделали переключение между ними простым процессом и предоставили возможность полностью отключить искусственный интеллект для тех, кто этого желает.
Говоря простым языком, Brave считает искусственный интеллект (AI) фундаментальным инструментом для операций поиска и ожидает его дальнейшего развития. Brave часто предоставляет ответы с использованием AI на различные поисковые запросы, обязательно указывая источники. Пользователи могут выключить использование AI в Brave по своему усмотрению. Тем не менее, как заявил главный специалист по поиску Хосеп Пужол, переход к AI-поиску является неизбежной тенденцией из-за его удобства — качества, которому люди неизменно отдают предпочтение. Искусственный интеллект изменяет интернет множеством способов: некоторые изменения являются положительными, другие же могут быть негативными. Например, AI может немного сэкономить время, особенно при сложных запросах с длинным хвостом. Однако важно отметить, что эти функции AI иногда могут предоставлять неверную информацию, хотя это не всегда очевидно.
По сути, данный подход напоминает концепцию агентского поиска Google, но с более тонким подходом. Вместо простого ответа на запросы, Google стремится понять намерения за ними. Таким образом, искусственно порождаемые ответы могут сэкономить пользователям драгоценное время, даже если системе нужно некоторое время для проведения множественных поисков и составления более подробного обзора темы. Хотя этот метод может занять несколько минут, он часто оказывается быстрее, чем выполнение отдельных поисковых запросов и ручное просеивание результатов. По мере появления новых возможностей традиционный поиск постепенно может превратиться в специализированную услугу.
Пужоль задавался вопросом, будут ли эти десять синих ссылок, которые мы видим сейчас, существовать через 10 лет. Однако более правильным было бы спросить, существуют ли они вообще сейчас. В следующее десятилетие поисковые системы могут превратиться в более разговорные AI или даже агентов, поэтому кажется вероятным их значительное изменение. Одно несомненно: потребность поиска информации останется актуальной. Поиск — это действие, которое мы выполняем, и независимо от того, делаем ли мы его напрямую или через агента, оно остаётся необходимостью.
На платформе Kaghi Влад предполагает, что искусственный интеллект (AI) со временем станет обычным способом получения информации. Тем не менее важно отметить, что их поисковая система не принуждает пользователей использовать AI для поиска. Наоборот, на Kaghi можно расширить область использования AI при проведении поисков, задавая дополнительные вопросы при необходимости. Забавно, если вы включите знак вопроса в свой запрос, AI активируется автоматически. Однако это только начало — есть еще многое другое, что стоит изучить и воспользоваться на Kaghi!
В недавнем заявлении Преловац заявил: ‘Star Trek не предполагает нажатие на ссылки, и я разделяю это убеждение — к тому времени, когда моей дочери исполнится 10 лет, она, возможно, тоже перестанет нажимать на них. Главный вопрос заключается в том, приведет ли существующая технология нас к этому. Однако у меня есть опасения относительно LLMs (моделей обучения языкам), поскольку они действительно имеют некоторые ограничения. На самом деле кажется маловероятным, что мы достигнем уровня технологий из Star Trek с помощью этих моделей.’
Если мы рассматриваем ИИ прежде всего как инструмент для поиска данных, будущее становится неопределенным. Когда генеративные ИИ берут верх, вопросы связанные с авторитетом и точностью могут быть переданы языковым моделям, которые иногда действуют непредсказуемо и сложно для понимания. Независимо от того, идет ли речь о расширении или сокращении возможностей ИИ, сохранении господства Google или наступлении нового периода разнообразия, очевидно одно: на горизонте происходят значительные изменения в способах получения информации.
Может быть, если нам удастся собрать множество поисковых стартапов, некоторые из них сосредоточатся на традиционных результатах поиска по десяти ссылкам. Пусть все будет к лучшему.
Смотрите также
- Я рассмотрел пару крошечных наушников, которые помогли мне лучше спать
- OP криптовалюта и прогнозы цен на OP
- NVIDIA хочет, чтобы геймеры выбирали подходящий пресет модели DLSS 4.5 для своей RTX GPU.
- Все фильмы ужасов, выходящие в 2026 году.
- Обзор RingConn Gen 2: умное кольцо, экономящее деньги
- 20 лучших циферблатов Samsung Galaxy Watch, которые вам стоит использовать
- Очень странные дела 5 подтверждают, почему Векна похищает детей в 4-й серии (и причина жуткая)
- 6 лучших планшетов для путешествий в 2024 году
- Обзор Pimax Crystal Light: новый стандарт доступного ПК VR
- 5 телефонов, которые стоит купить вместо Samsung Galaxy Z Fold 6
2025-06-06 16:26