
По четвергам, «Начальные лаборатории» представили новую модель языка ИИ под названием Mercury Coder. В этой инновационной модели используются методы диффузии, чтобы вытащить текст на скорости, превышающей обычные модели. В отличие от традиционных моделей, которые конструируют текст по одному слову за раз-как и те, кто питает CHATGPT-модели, основанные на диффузии, такие как Mercury, создают целые ответы одновременно, полируя их из изначально скрытого состояния в когерентный текст.
Купил акции по совету друга? А друг уже продал. Здесь мы учимся думать своей головой и читать отчётность, а не слушать советы.
Прочитать отчет 10-KВместо последовательно построения текста слева направо, по одному слову за раз, как традиционные крупные языковые модели делают с использованием авторегрессии, эти новые модели на основе диффузии работают по-разному. Они черпают вдохновение из методов генерации изображений, таких как стабильная диффузия, Dall-E и Midjourney. Такие модели, как LLADA (созданная исследователями из Университета Ренмина и Ant Group) и Mercury, используют подход маскировки. Эти модели начинаются с совершенно скрытого контента и постепенно удаляют шум или размытие с выхода, в конечном итоге раскрывая весь ответ одновременно.
В отличие от диффузионных моделей изображения, которые добавляют непрерывные колебания интенсивности пикселей, модели диффузии текста не могут вводить непрерывные вариации в отдельные части текстовых данных (слова или фразы). Вместо этого они заменяют эти части токенами -заполнителями, функционируя как текстовый эквивалент шума. Уровень маскировки в LLADA определяет количество шума, где высокая скорость маскировки приравнивается к высокой шуме, а низкая скорость маскирования означает низкий шум. По мере развития процесса диффузии он переходит от высокого уровня шума к низким уровням шума. Хотя LLADA выражает эту идею, используя маскирующий язык, а Mercury использует шумовую терминологию, обе модели используют аналогичную концепцию для генерации текста на основе процессов диффузии.
Как технический энтузиаст, я бы сказал, что создание модели синтеза изображения несколько похоже на то, как исследователи строят модели диффузии текста. Они делают это путем обучения нейронной сети данных, которые были преднамеренно скрыты, что позволяет модели предсказать, что должно заполнить пробелы. Затем прогнозы сравниваются с фактическими ответами. Если модели удается правильно угадать, соединения в нейронной сети, которые привели к правильному ответу, усиливаются. С достаточной практикой эти модели могут генерировать выходы, которые являются точными или достаточно убедительными, чтобы быть практическими инструментами.
Метод начальных лабораторий позволяет модели исправить и улучшить ее результаты, не ограничиваясь рассмотрением только текста, который он ранее произвел. Эта многозадачная возможность-это то, что позволяет Меркурию генерировать более тысячи токенов в секунду на графических процессорах NVIDIA H100, как сообщается.
Эти диффузионные модели демонстрируют более быстрые или эквивалентные характеристики для традиционных моделей аналогичного размера. По словам исследователей LLADA, их модель параметров на 8 миллиардов демонстрирует производительность, сопоставимую с показателями Llama3 8b по многочисленным критериям, обеспечивая конкурентные результаты в таких задачах, как MMLU, ARC и GSM8K.
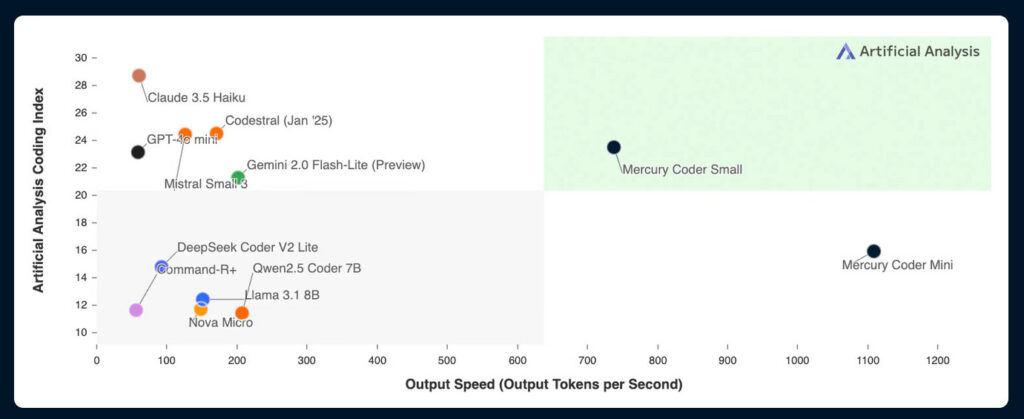
Несмотря на то, что Меркурий утверждает значительные усовершенствования скорости, Mercury Coder Mini достигает впечатляющих баллов-88,0% на Humaneval и 77,1% на MBPP, которые сравнимы с результатами GPT-4O Mini. Однако, как говорят, он работает на удивительных 1,109 токенах в секунду по сравнению с 59 токенами Mini GPT-4O в секунду. Это приводит к примерно на 19x более высокую скорость, чем MINI GPT-4O, сохраняя при этом аналогичные характеристики на кодирующих тестах.
Согласно документации Mercury, их модели могут работать более чем на 1000 токенов в секунду на NVIDIA H100. Эта скорость была достижимой только ранее со специализированным оборудованием от таких компаний, как Groq, Cerebras и Sambanova. По сравнению с другими высокоскоростными моделями, Mercury Coder Mini, как говорят, примерно в 5,5 раза быстрее, чем Flash-Lite Gemini 2.0 (который работает на уровне 201 токенов в секунду) и примерно в 18 раз быстрее, чем Claude 3,5 Хайку (работая с 61 токенами в секунду).
Раскрытие потенциальных новых возможностей в LLM
Диффузионные модели поставляются с определенными компромиссами. В отличие от обычных моделей, которые требуют только одного прохода для каждого токена, они часто требуют нескольких проходов по всей сети, чтобы получить полный ответ. Тем не менее, благодаря своей способности обрабатывать все токены одновременно, диффузионные модели удается поддерживать более высокую эффективность, уравновесив эти дополнительные затраты.
Начало считает, что преимущества скорости могут значительно повлиять на программное обеспечение, такое как инструменты завершения кода, где ответы Swift могут повысить эффективность разработчика. Более того, это может быть актуально для разговорного ИИ, ограниченных ресурсов, таких как мобильные приложения, и агенты искусственного интеллекта, требующие немедленного времени отклика.
Как аналитик, я взволнован потенциальным влиянием языковых моделей на основе диффузии на эволюцию генерации текста ИИ. Эти модели, кажется, набирают баланс между поддержанием качества и повышением скорости, что может революционизировать нашу область. До сих пор я заметил, что исследователи ИИ были восприимчивы к новым подходам, что указывает на готовность принять изменения и продвигать наше понимание еще больше.
Саймон Уиллисон, независимый исследователь искусственного интеллекта, выразил удовольствие от Ars Technica о текущих экспериментах с альтернативными дизайнами для трансформаторов. Он видит в этом свидетельство обширной, неисследованной территории в области крупных языковых моделей (LLMS), которую мы едва поцарапали поверхность.
Что касается основания, Андрей Карпати (ранее исследователь в Openai) выразил, что эта модель может потенциально проявлять различное поведение, возможно, выявление новых психологических аспектов или уникальных сильных и слабых сторон. Он призывает других экспериментировать с этим.
Неясно, могут ли более крупные диффузионные модели конкурировать с производительностью GPT-4O и Claude 3.7 Sonnet, когда речь идет о задачах обработки, особенно тех, которые включают сложные моделируемые рассуждения. Кроме того, есть вопрос об их способности эффективно масштабироваться. На данный момент эти модели служат альтернативами для более мелких языковых моделей ИИ, которые, кажется, поддерживают свою силу без значительного замедления.
На демонстрационном сайте «Начало» не стесняйтесь экспериментировать с Mercury Coder напрямую. В качестве альтернативы, вы можете скачать код LLADA или проверить его на платформе Hugging Face.
Смотрите также
- 20 лучших циферблатов Samsung Galaxy Watch, которые вам стоит использовать
- Я думал, что этот Android-телефон за 250 долларов станет катастрофой. Это не было
- Принудительное обновление Windows выйдет в следующем месяце
- Новая функция Canvas в ChatGPT очень похожа на Артефакты Клода.
- Первые впечатления: Обзор Samsung Galaxy A57 5G
- Цены на AppleCare+ только что выросли: что вам нужно знать
- В фильме «Дыра» с Тео Джеймсом в главной роли задействована звезда «Игры кальмаров» Хоён
- Релиз 4-го сезона Ted Lasso: Идеальный момент для шутки о Чемпионате мира.
- Агент Сверху: Амбициозный фэнтезийный сериал 2026 года от Netflix из Тайваня
- Mastercard получила пометку от сообщества X на пост, утверждающий, что компания не подвергает цензуре игровой контент
2025-02-28 02:25