
Cloudflare, компания, поддерживающая множество веб-сайтов, незаметно внесла изменения в свои настройки в попытке повлиять на то, как Google использует их контент для искусственного интеллекта. Этот шаг может иметь значительные последствия для того, как веб-сайты доступны и используются программами искусственного интеллекта Google.
Купил акции по совету друга? А друг уже продал. Здесь мы учимся думать своей головой и читать отчётность, а не слушать советы.
Прочитать отчет 10-KМы взяли интервью у генерального директора Cloudflare Мэтью Принса, чтобы понять текущую ситуацию, её важность и то, как может развиваться интернет. Прежде чем углубиться в детали, давайте рассмотрим необходимую справочную информацию.
Как энтузиаст технологий, я внимательно следил за шумихой вокруг новой ‘Политики контентных сигналов’ от Cloudflare. Это прямой ответ на опасения издателей и веб-сайтов, которые заметили значительное падение трафика с момента появления обзоров AI от Google – и подобных функций ответов AI. По сути, эти сайты говорят, что AI от Google дает ответы *без* перенаправления людей к исходному источнику информации, что действительно наносит ущерб их доходам. Это серьезно, потому что это влияет на то, как контент-мейкеры получают оплату!
Хотя было предпринято множество попыток решить эту проблему – включая судебные иски и создание новых платформ для предоставления компенсации – мало компаний обладают таким же влиянием, как Cloudflare. Они поддерживают примерно 20% всех веб-сайтов, что означает, что большая часть того, что вы видите в интернете и что питает AI модели, зависит от их услуг.
По словам Принса, большинство компаний, занимающихся искусственным интеллектом, готовы платить за контент, пока все соблюдают одни и те же правила. Однако они обеспокоены тем, что Google получит контент бесплатно, что даст ей несправедливое преимущество над конкурентами, которые платят.
Google использует свою власть в поисковой системе, чтобы подталкивать веб-сайты к разрешению Google использовать их контент, даже если эти веб-сайты обычно не согласились бы на это.
Изменяющиеся нормы веба
Я заметил, что с 2023 года Google предоставил владельцам веб-сайтов возможность предотвратить использование их контента для обучения своих AI-моделей, таких как Gemini. По сути, они могут попросить Google не учиться на своем сайте.
Если вы хотите, чтобы Google показывал ваши страницы в результатах поиска, вам также нужно знать, что Google может использовать этот контент для создания AI-powered сводок в верхней части этих результатов. Этот процесс, называемый retrieval-augmented generation (RAG), означает, что Google использует информацию с ваших страниц для быстрого ответа на вопросы пользователей.
Это не так для многих других краулеров, что делает Google исключением среди основных игроков.
Как пользователь веб-сайта, я знаю, что это действительно разочаляющая проблема для множества различных сайтов – от новостных организаций, публикующих важные статьи, до финансовых компаний, делящихся своими исследованиями. Кажется, что все с этим борются!
Недавнее исследование, проведенное Pew Research Center в июле, изучило данные 900 взрослых американцев и обнаружило, что AI Overviews от Google значительно снизили количество переходов на веб-сайты. Когда AI Overviews появлялись в верхней части результатов поиска, пользователи переходили по ссылке только в 8% случаев, по сравнению с 15%, когда эти краткие обзоры отсутствовали.
Согласно недавнему отчету Wall Street Journal, крупные новостные организации, такие как The New York Times и Business Insider, столкнулись со значительным падением трафика на свои веб-сайты. Отчет, основанный на информации из различных источников, включая внутренние данные, предполагает, что это снижение связано с ростом AI-обобщений и уже привело к сокращениям рабочих мест и изменениям в стратегии компании.
В прошлом августе Лиз Рид, возглавляющая поиск в Google, опровергла сообщения о том, что меньше людей переходят по ссылкам в результатах поиска Google. Она заявила, что общее количество органических переходов на веб-сайты осталось стабильным по сравнению с предыдущим годом. Рид объяснила, что многие сообщения о значительном снижении основывались на неточных данных, конкретных случаях, которые не отражали общую картину, или изменениях в трафике веб-сайтов, произошедших до того, как Google представил новые AI-функции в Search.
Издатели скептически относятся к AI Overviews от Google. Penske Media Corporation, владелец изданий, таких как The Hollywood Reporter и Rolling Stone, подала в суд на Google в сентябре, утверждая о значительном падении доходов от партнерских ссылок – более 30% за последний год. Они в значительной степени приписывают эту потерю AI Overviews от Google, что особенно беспокоит бизнес с уже узкими прибыльными маржами.
Penske утверждал, что Google объединяет стандартные результаты поиска с выдержками, созданными с использованием Retrieval-Augmented Generation (RAG). Из-за этой интеграции блокировка Google от суммирования их статей невозможна — потеря трафика из Google Search серьезно повредит их финансам.
С самого начала существования интернета, обмен контентом – или ‘рефералы’ – был необходим для того, как веб-сайты зарабатывают деньги. Веб-сайты всегда делали свой контент доступным бесплатно для всех, включая поисковые системы, и существовало понимание, что это позволяет создателям контента получать признание за свою работу и зарабатывать доход для продолжения творчества.
Я замечаю, что в последнее время возникает много опасений, что традиционный способ суммирования контента больше не справляется, особенно с ростом таких техник, как RAG. Кажется, что все, включая Cloudflare, работают над установлением новых, более релевантных стандартов для решения этой проблемы.
Масштабное обновление robots.txt
Недавно я узнал о новой политике контентных сигналов от Cloudflare, о которой они объявили 24 сентября. По сути, они используют свой охват, чтобы попытаться повлиять на то, как веб-краулеры получают доступ к контенту в Интернете и используют его. Они планируют сделать это, автоматически обновляя файлы robots.txt на миллионах веб-сайтов.
Начиная с 1994 года, веб-сайты стали использовать файл с именем ‘robots.txt’, чтобы сообщать поисковым ботам, какие страницы сканировать и включать в результаты поиска, а какие оставить в покое. Со временем это стало стандартной практикой, и веб-краулеры Google всегда уважали эти инструкции.
Традиционно, файл robots.txt представлял собой простой список, сообщающий веб-краулерам, к каким частям веб-сайта им разрешено или не разрешено обращаться. Хотя это и не строгое правило, это работало хорошо как джентльменское соглашение. Владельцы веб-сайтов выигрывали, контролируя, что могут видеть краулеры, а краулеры экономили время и ресурсы, пропуская нерелевантные данные.
Файл robots.txt просто контролирует, могут ли поисковые роботы *достичь* веб-страницы, а не *как* они могут использовать информацию на ней. Например, Google позволяет владельцам веб-сайтов блокировать конкретного робота под названием ‘Google-Extended’, чтобы предотвратить использование его контента для обучения модели Gemini AI. Однако это правило применяется только в будущем — оно не отменяет никакой подготовки, которая уже произошла до того, как правило было введено в действие, и не предотвращает использование Google контента для таких функций, как RAG и AI Overviews.
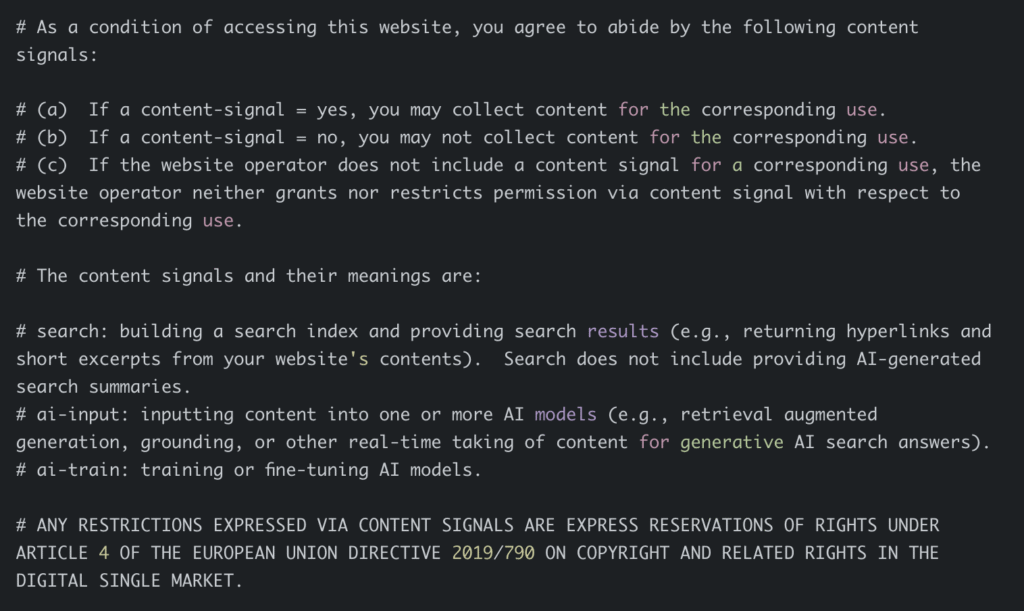
Политика сигналов контента – это новое предложение о том, как веб-сайты могут сообщать поисковым системам, какой контент они разрешают использовать. Она позволяет владельцам веб-сайтов выбирать, разрешать или не разрешать определенные способы использования их контента, как это определено в самой политике.
- search: Построение поискового индекса и предоставление результатов поиска (например, возврат гиперссылок и коротких отрывков из содержимого вашего веб-сайта). Поиск не включает предоставление AI-сгенерированных поисковых сводок.
- ai-input: Ввод контента в одну или несколько AI-моделей (например, retrieval augmented generation, grounding, или другое получение контента в реальном времени для генеративных AI-ответов на поисковые запросы).
- ai-train: Обучение или тонкая настройка AI-моделей.
Cloudflare упростила для всех своих клиентов настройку этих параметров по мере необходимости. Кроме того, она автоматически обновила файлы robots.txt для 3,8 миллиона веб-сайтов, уже использующих инструмент управления robots.txt от Cloudflare. По умолчанию эти обновления разрешают сканирование поисковыми системами, предотвращают обучение ИИ и оставляют поле ввода ИИ пустым, сигнализируя о нейтральной позиции.
Угроза потенциального судебного разбирательства
Я заметил, что Cloudflare структурирует это объявление так, чтобы оно напоминало соглашение об условиях обслуживания, и это довольно понятно, почему. Они напрямую пытаются заставить Google пересмотреть, как он сочетает обычный веб-краулинг с новой функцией AI Overviews – по сути, они используют юридическое давление, чтобы добиться изменения политики.
По словам Принца, юристы Google обращают внимание и осознают, что им придется намеренно игнорировать эту проблему на значительной части интернета.
Он описал это как попытку побудить компанию, которая, по его мнению, в целом действовала ответственно и поддерживала интернет, вернуться к этим позитивным практикам.
Он объяснил, что в Google идёт внутреннее обсуждение. Некоторые люди считают, что им следует изменить свой текущий подход, в то время как другие утверждают, что это означало бы потерю ключевого преимущества и отказ от претензий на весь онлайн-контент.
В связи с продолжающимися обсуждениями об использовании данных, юридическая команда Google обладает значительным влиянием. Cloudflare отреагировала, разработав инструменты для обеспечения того, чтобы у любых отслеживаемых ими веб-сайтов была чётко определённая и поддающаяся принудительному исполнению лицензия. По словам Принса, этот подход направлен на создание юридических последствий для тех, кто не соблюдает условия лицензии.
Следующая веб-парадигма
Только такая крупная компания, как Cloudflare, могла бы реалистично внедрить это изменение и ожидать, что оно принесет результат. Если бы лишь небольшое количество веб-сайтов это сделали, Google мог бы легко проигнорировать это, или даже полностью прекратить посещение этих сайтов. Однако, поскольку Cloudflare работает со столькими веб-сайтами, Google не может позволить себе игнорировать это изменение или блокировать эти сайты, не нанеся значительного вреда результатам поиска.
Cloudflare стремится к здоровому интернету, но также учитывает и собственные бизнес-цели. Они разрабатывают инструменты, чтобы помочь веб-сайтам использовать Retrieval-Augmented Generation (RAG), работая над этим с Bing. Они также тестировали систему, в которой веб-сайты могут взимать плату с компаний, которые собирают их контент для целей искусственного интеллекта, хотя детали этой системы все еще прорабатываются.
Я спросил Принца, связано ли его участие со твердой верой в проект. Он объяснил, что возможности изменить что-то столь значительное, как интернет, встречаются редко. Он считает важным учитывать как положительные, так и отрицательные уроки истории интернета, поскольку они строят для него лучшее будущее.
Мы всё ещё выясняем, как веб будет зарабатывать деньги в будущем. Cloudflare имеет некоторые идеи, а другие предлагают новые способы его создания и финансирования – такие как новые стандарты и онлайн-маркетплейсы. Вероятно, некоторые компании добьются успеха, а другие нет, и успешные компании могут отличаться от тех, кто процветал в прошлом.
Большинство людей, независимо от своих собственных интересов, согласны с тем, что Google не должен автоматически побеждать в следующем поколении веб, даже если в настоящее время он лидирует в поиске. Тот факт, что Google преуспел в традиционном поиске, не означает, что он заслуживает доминировать в будущем веб, работающем на основе систем ответов.
Цель обновленного стандарта robots.txt заключается в том, чтобы позволить Google показывать контент в обычных результатах поиска, но предотвратить его появление в AI Overviews. Независимо от того, как это происходит — будь то из-за давления со стороны таких компаний, как Cloudflare, или по другой причине — большинство людей согласны с тем, что это был бы положительный первый шаг.
Смотрите также
- Я думал, что этот Android-телефон за 250 долларов станет катастрофой. Это не было
- 20 лучших циферблатов Samsung Galaxy Watch, которые вам стоит использовать
- Обзор PrivadoVPN: новый бюджетный VPN, которым можно пользоваться бесплатно
- Первые впечатления: Обзор Samsung Galaxy A57 5G
- Новая функция Canvas в ChatGPT очень похожа на Артефакты Клода.
- Добро пожаловать в шоураннер Дерри, который возглавит серию приквелов «Пятница 13-е» в Peacock
- Наконец-то я нашел утилиту для игрового ноутбука, которую действительно стоит использовать
- Ключевой отсылки «Мгните и пропустите» из 2 сезона The Pitt к оригинальной трагедии, объясненной вернувшимся актером.
- Я впервые использую Amazon Kindle Scribe — и мне это нравится.
- Whoop против Garmin: сравнение брендов носимых устройств
2025-10-16 15:27